请注意,本文编写于 154 天前,最后修改于 152 天前,其中某些信息可能已经过时。
目录
部署K8S集群的高可用性
接上篇,为确保 K8s 集群的高可用性,可以配置 haproxy 和 keepalived。这样可以避免单个节点故障导致服务不可用,从而实现集群的高可用性。
安装haproxy和keepalived,在两台Master节点上安装
yum install haproxy keepalived -y
修改配置文件,添加master节点配置负载均衡算法为轮询
vim /etc/haproxy/haproxy.cfg frontend k8s #定义一个前端命名为k8s,负责接收客户端的请求,并将其转发到后端 bind *:16443 #监听16443端口 mode tcp #以TCP模式运行 option tcplog #启用TCP日志记录 tcp-request inspect-delay 5s #请求延迟为5秒 default_backend k8s #关联后端名 backend k8s #定义一个后端,将前端的请求转发到后端的真实服务器中 mode tcp option tcplog option tcp-check balance roundrobin #设置负载均衡规则为轮询,按顺序将流量分配给后端服务器 default-server inter 10s downinter 5s rise 2 fa11 2 slowstart 60s maxconn 250 maxqueue 256 weight 100 #设置服务器健康检查间隔为10秒,如果服务器被标记为不可用则5秒检查一次,服务器需连续两次健康检查通过才被标记为可用状态,服务器在健康检查失败两次后标记为不可用,请求队列最大为256,权重为100 server k8s-server 192.168.3.1:6443 check #定义后端真实服务器+端口,启用check健康检查 server k8s-node2 192.168.3.2:6443 check
将配置文件复制到另一台master节点上
scp /etc/haproxy/haproxy.cfg k8s-node1:/etc/haproxy/
启动服务,并设置为开机自启,在所有master节点上都要操作
systemctl start haproxy.service systemctl enable haproxy.service
配置keepalived,关联监测脚本
vim /etc/keepalived/keepalived.conf ! Configuration File for keepalived global_defs { router_id K8S-2 script_user root enable_script_security } vrrp_script check_server{ script "/etc/keepalived/check.sh" interval 3 #脚本运行的间隔时间为 3 秒。 weight -10 #如果脚本失败,权重减少10。 fall 2 #连续两次脚本失败后,状态被认为是不可用。 rise 1 #脚本成功一次后,状态被认为是可用。 } vrrp_instance VI_1{ state BACKUP #设置 VRRP 实例的初始状态为 BACKUP,主节点则设置为MASTER interface ens224 #指定 VRRP 实例使用的网络接口为 ens224。 mcast_src_ip 192.168.3.2 #设置为本机IP virtual_router_id 51 #设置虚拟组ID 为51,主备服务器需在同一个组里 priority 50 #设置优先级 advert_int 2 #设置心跳检测时间。 authentication{ #配置主备之间的认证 auth_type PASS auth_pass 123 } virtual_ipaddress{ #设置VIP 192.168.3.254/24 } track_script{ #关联检测脚本 check_server } }
编写检测脚本,将其放在keepalived目录下用于监控haproxy服务进程,当该进程不在时则关闭当前节点的keepalived服务
#!/usr/bin/env bash if pgrep haproxy 1>/dev/null ;then true else systemctl stop keepalived.service exit 1 fi
将配置文件与脚本复制一份给另一台Master服务器,以此组成K8S的高可用
scp /etc/keepalived/keepalived.conf k8s-node1:/etc/keepalived/ scp /etc/keepalived/check.sh k8s-node1:/etc/keepalived/
故障切换测试手动关闭MASTER节点的haproxy服务,查看VIP是否会切换至备份节点中
systemctl stop haproxy
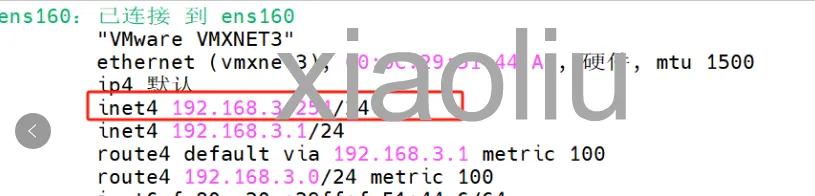
关闭后VIP自动切换
 在备份节点中查看,VIP已经切换过来了
在备份节点中查看,VIP已经切换过来了
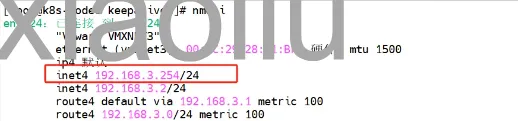 查询节点状态,命令可以正常执行
查询节点状态,命令可以正常执行

优化脚本
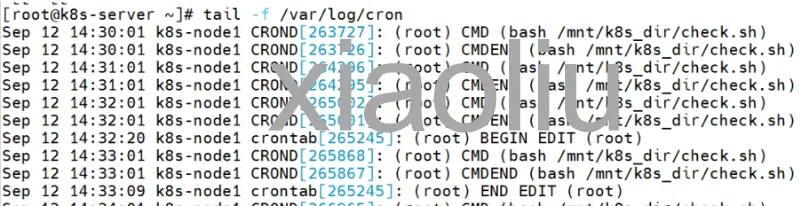
由于在检测到haproxy服务关闭后会将keepalived服务关闭,且服务恢复后VIP不会自动切换回来。可使用定时任务+脚本的方式,循环检测,当haproxy服务恢复后检查keepalived服务,如果未启动则执行启动命令以此来恢复MASTER身份
#!/usr/bin/env bash if pgrep haproxy 1>/dev/null ;then if systemctl status keepalived.service |grep "inactive" 1>/dev/null;then systemctl start keepalived.service else exit 0 fi fi
编写定时任务
*/1 * * * * bash /mnt/k8s_dir/check.sh
手动恢复haproxy服务
systemctl start haproxy
当触发定时任务时,VIP也自动切换回来了
如果对你有用的话,可以打赏哦
打赏


目录