请注意,本文编写于 154 天前,最后修改于 154 天前,其中某些信息可能已经过时。
目录
基于kraft的kafka集群部署
“ Kafka 3.0版本之后,可以脱离对zookeeper的依赖,由kraft来对集群的controller进行选举,大大增加了kafka的独立性,本文将mark一下基于kafka的kafka集群搭建过程”
01 kafka的基本构成
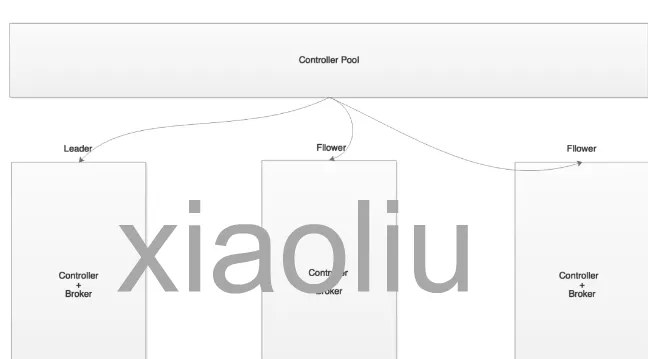
kafka集群是由多个kafka broker节点构成,在多个kafka的broker节点中,将会被选举出一个controller节点,该controller是一个特殊的角色,主要用来管理和协调整个kafka集群,对kafka的定时任务、事件队列、事件线程处理、zk监听等进行管理,具体主要包括:更新集群元数据信息、创建topic、删除topic、分区重分配、leader副本选举、topic分区扩展、broker加入集群、broker崩溃、受控关闭、controller leader选举等。
而这些元数据,kafka本身并不保存,而是通过zookeeper进行存储,即zookeeper在kafka中主要承担了:
- 管理Kafka broker节点的状态信息,比如broker的上下线状态、topic分区信息、副本信息等;
- 存储和管理Kafka集群的元数据信息和配置信息,
- 监控Kafka broker节点的状态信息,帮助Kafka集群实现自动故障转移和负载均衡等功能。
- Kafka的broker集群中的controller的选择,通过zk的临时节点争抢获得。 因此,kafka的正常运行,无法脱离zookeeper。 但在kafka 3.0以上的版本中,kafka自身引入了kraft机制,其相关的元数据也可以保存到controller的节点中了。因此,我们也可以认为,在kafka 3.0版本后,它可以不依赖于zookeeper进行执行。
02—kafka集群部署规划
在版本2.8之前,kafka集群部署必须依赖zookeeper。在构建整个kafka集群的时候,我们可以不对broker的数量进行限制,但是需要保证提前创建一个奇数个节点的zookeeper集群;
在3.0之后,kafka引入kraft模式,在该模式下则无需通过zookeeper进行管理,但是为了保证集群的可靠性,我们需要保证kafka集群主机的数量为奇数个。
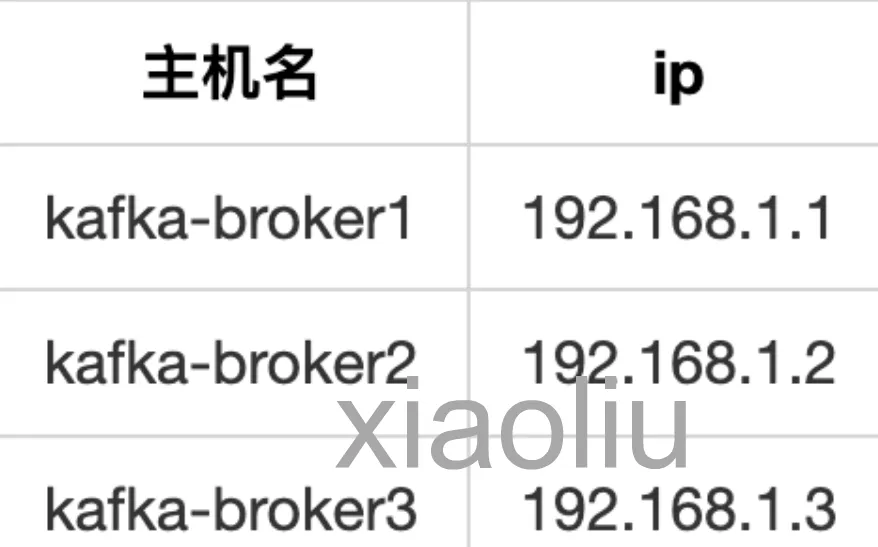
集群规划:
03—kafka集群部署步骤
解压文件
tar -xvzf kafka_2.13-3.6.0.tgz -C /apps
修改配置文件
cd /apps/kafka_2.13-3.6.0/config/kraft vi server.properties 需要修改的内容包括: # 服务器的角色。这个设置将会使该节点进入kraft模式,其中角色可以分为controller和broker,即该节点可以作为broker,同时也可以作为controller process.roles=broker,controller # 设置节点的id,每个节点的id必须不一样 node.id=1 # 设置controller集群(默认管理节点端口为9093,这里我们设置为19093) controller.quorum.voters=1@192.168.1.1:19093,2@192.168.1.2:19093,3@192.168.1.3:19093 # 带有PLAINTEXT监听名称使用端口19092,带有CONTROLLER的监听名称使用19093 # FORMAT: # listeners = listener_name://host_name:port # EXAMPLE: # listeners = PLAINTEXT://your.host.name:19092# 或者# listeners = PLAINTEXT://your.host.name:19092,CONTROLLER://192.168.1.1:19093 #不同服务器绑定的端口listeners=PLAINTEXT://192.168.1.1:19092,CONTROLLER://192.168.1.1:19093 # 监听器名称、主机名和代理将向客户端公布的端口.(broker 对外暴露的地址) # 如果未设置,则使用"listeners"的值. advertised.listeners=PLAINTEXT://192.168.1.1:19092 其他参数可根据实际去需求进行更改。
其他节点修改
node2:
# 服务器的角色。这个设置将会使该节点进入kraft模式,其中角色可以分为controller和broker,即该节点可以作为broker,同时也可以作为 controllerprocess.roles=broker,controller # 设置节点的id,每个节点的id必须不一样 node.id=2 # 设置controller集群(默认管理节点端口为9093,这里我们设置为19093) controller.quorum.voters=1@192.168.1.1:19093,2@192.168.1.2:19093,3@192.168.1.3:19093 # 带有PLAINTEXT监听名称使用端口19092,带有CONTROLLER的监听名称使用19093 # FORMAT: # listeners = listener_name://host_name:port # EXAMPLE: # listeners = PLAINTEXT://your.host.name:19092 # 或者 # listeners = LAINTEXT://your.host.name:19092,CONTROLLER://192.168.1.1:19093 #不同服务器绑定的端口listeners=PLAINTEXT://192.168.1.2:19092,CONTROLLER://192.168.1.2:19093 # 监听器名称、主机名和代理将向客户端公布的端口.(broker 对外暴露的地址) # 如果未设置,则使用"listeners"的值. advertised.listeners=PLAINTEXT://192.168.1.2:19092 其他参数可根据实际去需求进行更改。
node3:
# 服务器的角色。这个设置将会使该节点进入kraft模式,其中角色可以分为controller和broker,即该节点可以作为broker,同时也可以作为 controllerprocess.roles=broker,controller # 设置节点的id,每个节点的id必须不一样 node.id=3 # 设置controller集群(默认管理节点端口为9093,这里我们设置为19093) controller.quorum.voters=1@192.168.1.1:19093,2@192.168.1.2:19093,3@192.168.1.3:19093 # 带有PLAINTEXT监听名称使用端口19092,带有CONTROLLER的监听名称使用19093 # FORMAT: # listeners = listener_name://host_name:port # EXAMPLE: # listeners = PLAINTEXT://your.host.name:19092 # 或者 # listeners = PLAINTEXT://your.host.name:19092,CONTROLLER://192.168.1.1:19093#不同服务器绑定的端口listeners=PLAINTEXT://192.168.1.3:19092,CONTROLLER://192.168.1.3:19093 # 监听器名称、主机名和代理将向客户端公布的端口.(broker 对外暴露的地址) # 如果未设置,则使用"listeners"的值. advertised.listeners=PLAINTEXT://192.168.1.3:19092 其他参数可根据实际去需求进行更改。
生成随机uuid
/apps/kafka_2.13-3.6.0/bin/kafka-storage.sh random-uuid 会随机输出一个uuid值,比如: 9WbxA-qWMNFv-WAbLQ53Mx
注册集群服务(每个节点执行)
用生成的uuid格式化目录,让三个节点配置认定为同一个集群(在每一个节点执行):
/apps/kafka_2.13-3.6.0/bin/kafka-storage.sh format -t 9WbxA-qWMNFv-WAbLQ53Mx -c /apps/kafka_2.13-3.6.0/config/kraft/server.properties
启动服务启动服务,在各个节点执行:
/apps/kafka_2.13-3.6.0/bin/kafka-server-start.sh -daemon /apps/kafka_2.13-3.6.0/config/kraft/server.properties 也可以通过nohup的方式启动: nohup sh /apps/kafka_2.13-3.6.0/bin/kafka-server-start.sh /apps/kafka_2.13-3.6.0/config/kraft/server.properties > /apps/kafka_2.13-3.6.0/startkafka.out &
检查状态
对于状态检查,可以通过kafka-cluster.sh、kafka-metadata-quorum.sh脚本进行检查,该脚本主要是用于检查kraft模式下集群元数据的状态。
查看集群id /apps/kafka_2.13-3.6.0/bin/kafka-cluster.sh --bootstrap-server 192.168.1.1:19092,192.168.1.2:19092,192.168.1.3:19092 cluster-id 查看集群信息以及状态 /apps/kafka_2.13-3.6.0/bin/kafka-metadata-server.sh --bootstrap-server 192.168.1.1:19092,192.168.1.2:19092,192.168.1.3:19092 describe --status 查看节点角色 /apps/kafka_2.13-3.6.0/bin/kafka-metadata-server.sh --bootstrap-server 192.168.1.1:19092,192.168.1.2:19092,192.168.1.3:19092 --replication
创建topic
./kafka-topics.sh --bootstrap-server 192.168.1.1:19092,192.168.1.2:19092,192.168.1.3:19092 --create --topic socketTopic --partitions 3 --replication-factor 2
查看topic
查看存在的topic列表: ./kafka-topics.sh --bootstrap-server 192.168.1.1:19092,192.168.1.2:19092,192.168.1.3:19092 --list 查看topic的详细信息: ./kafka-topics.sh --bootstrap-server 192.168.1.1:19092,192.168.1.2:19092,192.168.1.3:19092 --describe
如果对你有用的话,可以打赏哦
打赏


目录